为获得在某一搜索引擎中的排名,您根据其排名规律,精心设计某一页面,使其符合得很好,登记后也获得理想的排名。由于各搜索引擎排名规则各异,您的某一页面能获得某一搜索引擎中的好的排名,但通常情况下,对于其他搜索引擎,排名就差得很远。
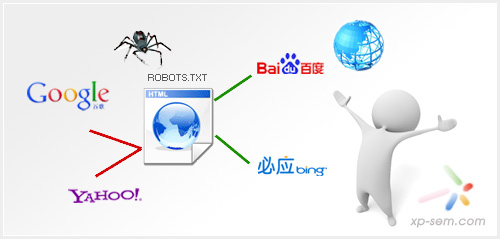
为此,有人在站点中复制出内容相同的不同文件名的页面,并对复制页面的原标记进行修改,以期符合其他搜索引擎排名规则。
然而,许多搜索引擎一旦发现您站点中有异常“克隆”页面,会给予惩罚,不收录您的页面。
Robots.txt就是为了解决这问题。
我们给出样本:
User-agent: {SpiderNameHere}
Disallow: {FileNameHere}
譬如,如果您想告诉Excite搜索引擎的Spider(ArchitextSpider),不检索您站点中三个特定页面,您可这样操作:
User-agent: ArchitextSpider
Disallow: /orderform.html
Disallow: /product1.html
Disallow: /product2.html
如果您不想让Excite的Spider检索在abc目录下的def.htm文件:
User-agent: ArchitextSpider
Disallow: /abc/def.htm
不检索整个mydirectory目录:
User-agent: ArchitextSpider
Disallow: /mydirectory/
不让所有Spider检索:
User-agent: *
不检索整个站点:
Disallow: /
我们给出其他实例:
User-agent: ArchitextSpider
Disallow: /abc/def.htm
User-agent: Infoseek
Disallow: /ghi/jkl.htm
User-agent: ArchitextSpider
User-agent: Infoseek
Disallow: /abc/def.htm
Disallow: /ghi/jkl.htm
如下列表为世界各大搜索引擎和其对应的User-Agent,供大家参考。
搜索引擎 User-Agent
AltaVista Scooter
Infoseek Infoseek
Hotbot Slurp
AOL Search Slurp
Excite ArchitextSpider
Google Googlebot
Goto Slurp
Lycos Lycos
MSN Slurp
Netscape Googlebot
NorthernLight Gulliver
WebCrawler ArchitextSpider
Iwon Slurp
Fast Fast
DirectHit Grabber
Yahoo Web Pages Googlebot
Looksmart Web Pages Slurp
小心Slurp,如果您不想让其检索一个页面,这会使多个其他搜索引擎也不检索该页面。通常,用Slurp的搜索引擎规则差不多。
一般,根目录下的页面排名要高于次目录下页面的排名,这是因为,搜索引擎有时会认为次目录下的URL可能没有自己独立域名或与他人共享主机。
如果多个递交页面内容丰富,相互不非常类似,或在原有页面基础上进行优化,您不必担心会遭搜索引擎惩罚,不必建立robots.txt文件。
如果您使用一个非常有用的页面但针对许多不同搜索引擎,您“克隆”出许多类似的页面,那您就必须考虑robots.txt。
robots.txt也可用在某一目录中。
转载请注明:范耀祖 » 为什么及如何建立一个Robots.txt文件?